
Mnih V, Badia A P, Mirza M, et al. Asynchronous methods for deep reinforcement learning[C]//International Conference on Machine Learning. 2016: 1928-1937. 2016 ICML
1. on-policy& off-policy
Sutton的书RL an introduction edition 2. 在5.4节 Monte Carlo Control without Exploring starts中,作者定义了on-policy与off-policy:
On-policy methods attempt to evaluate or improve the policy that is used to make decisions, whereas off-policy methods evaluate or improve a policy different from that used to generate the data.
一句话解释:其实就是只有一句话: 更新值函数时是否只使用当前策略所产生的样本.
 - on-policy:REINFORCE, TRPO, SARSA
- on-policy:REINFORCE, TRPO, SARSA
- off-policy:Q-learning, Deterministic policy gradient


2. Value-based RL & Policy-based RL
Def
- Value-based A policy is generated from value function:
\[ V_\theta (s)= V^\pi(s) \] \[ Q_\theta (s,a)= Q^\pi(s,a)\]
我们用线性非线性的方式对值函数进行逼近求解
- Policy-based RL:Directly parametrise the policy: \[ \pi_\theta(s,a)= P[a | s,\theta]\] The output is a probability.
用线性或非线性(如神经网络)对策略进行求解
Difference
- Value Based
- Learnt Value Function
- Implicit policy
先求值函数,然后用贪婪算法求策略,所以是隐含的:
- Policy Based
- No Value Function
- Learnt Policy
- Actor-Critic
- Learnt Value Function
- Learnt Policy

Policy-Based RL
- Advantages:
- Better convergence properties >基于策略的学习可能会具有更好的收敛性,这是因为基于策略的学习虽然每次只改善一点点,但总是朝着好的方向在改善;而价值函数在后期可能会一直围绕最优价值函数持续小的震荡而不收敛,同时有时候求解值函数非常复杂。
- Effective in high-dimensional or continuous action spaces
- Can learn stochastic policies
- Disadvantages:
- Typically converge to a local rather than global optimum
- Evaluating a policy is typically inefficient and high variance >原始基于策略的学习效率不够高,还有较高的变异性(方差,Variance)。因为基于价值函数的策略决定每次都是推促个体去选择一个最大价值的行为;但是基于策略的,更多的时候策略的选择时仅会在策略某一参数梯度上移动一点点,使得整个的学习比较平滑,因此不够高效。同时当评估单个策略并不充分时,方差较大。
Policy Optimisation
- Policy based reinforcement learning is an optimisation problem
所以这是一个优化问题,我们要做的是利用参数化的策略函数,通过调整这些参数来得到一个较优策略,遵循这个策略产生的行为将得到较多的奖励。具体的机制是设计一个目标函数,对其使用梯度上升(Gradient Ascent)算法优化参数以最大化奖励。
- Find θ that maximises J(θ)
而将策略表达成参数θ的目标函数,有如下几种形式,start value是针对拥有起始状态的情况下求起始状态 \(s_1\) 获得的奖励,average value针对不存在起始状态而且停止状态也不固定的情况,在这些可能的状态上计算平均获得的奖励。 Average reward per time-step为每一个时间步长在各种情况下所能得到的平均奖励。 > 目标函数的本质还是奖励。
- Compute Policy Gradient
如何来优化这个目标? 我们采用随即梯度算法来解决。


所以,现在我们得到所有形式的目标函数所对应的策略梯度是一样的,注意这里有两个部分组成,一个是策略函数的log形式,一个是引导奖励(score function)。第一部分是参数化直接得到的,第二部分可以直接用即时奖励来计算,也可以用值函数近似,也就是AC算法。
Policy Function
- softmax
- Gaussian
- Random
Score Function
根据Score Function的不同,对应不同的算法。如下图:

- Monte-Carlo Policy Gradient (REINFORCE) Using return vt as an unbiased sample of \(Q^{\pi_\theta}(s_t, a_t)\) > Monte-Carlo policy gradient still has high variance
3. Actor-Critic
Q Actor-Critic
We use a critic to estimate the action-value function \[ Q_w(s,a)\approx Q^{\pi_\theta}(s, a)\]
Actor-critic algorithms maintain two sets of parameters
-Critic Updates action-value function parameters w
-Actor Updates policy parameters θ, in direction suggested by critic
\[\Delta\theta=\alpha\nabla_\theta log \pi_\theta(s,a)Q_w(s, a)\]
可以明显看出,Critic做的事情其实是我们已经见过的:策略评估,他要告诉个体,在由参数 \(\theta\) 确定的策略 \(\pi_{\theta}\) 到底表现得怎么样。关于策略评估我们之前讲过,可以使用蒙特卡洛策略评估、TD学习以及TD(λ)等方式实现

在这个例子当中,我们只是用了线性的函数来估计Q,当然目前都是神经网络来计算了。另外,REINFORCE和Q AC有high variance的问题。因此有了如下的改进算法。
Advantage Actor-Critic
- advantage function
\[ V_v(s,a)\approx V^{\pi_\theta}(s, a)\] \[ Q_w(s,a)\approx Q^{\pi_\theta}(s, a)\] \[ A(s,a)= Q_w(s,a)-V_v(s,a)\] 
Training

如上图:我们说AC结合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法. Actor 基于概率选行为, Critic 基于 Actor 的行为评判行为的得分, Actor 根据 Critic 的评分修改选行为的概率。
结合到具体的网络上就是:Actor和Critic各为一个网络,Actor输入是状态输出的是动作,loss就是\(log\_prob * td\_error\),(和策略梯度相对应,注意到这里的loss和Policy Gradient中的差不多,只是vt换成td_error,引导奖励值vt换了来源(Critic给的)而已),Critic输入的是状态输出的是Q值,loss是\(MSE((r+\gamma*Q_{next}) - Q_{eval})\)也就是\(MSE(td\_error)\),也就是说这里更新critic对应Q-learning是一样的均方误差。
4. A3C
Asynchronous
DQN比传统RL算法有了巨大提升其中一个主要原因就是使用了经验回放的技巧。然而,打破数据的相关性,经验回放并非是唯一的方法。另外一种方法是异步的方法(异步的方法是指数据并非同时产生) 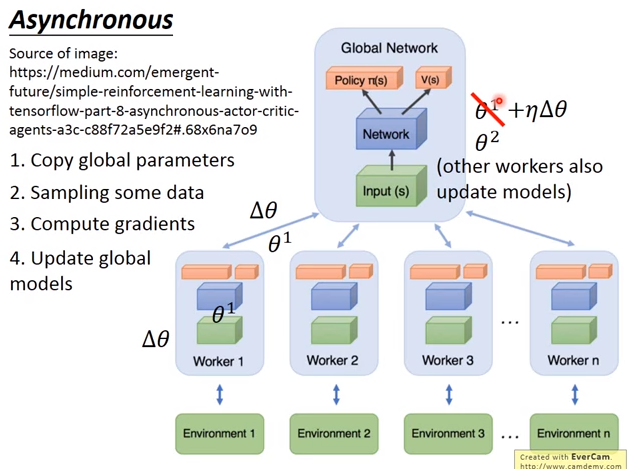 ## Advantage 相比DQN算法,A3C算法不需要使用经验池来存储历史样本并随机抽取训练来打乱数据相关性,节约了存储空间,并且采用异步训练,大大加倍了数据的采样速度,也因此提升了训练速度。与此同时,采用多个不同训练环境采集样本,样本的分布更加均匀,更有利于神经网络的训练。
## Advantage 相比DQN算法,A3C算法不需要使用经验池来存储历史样本并随机抽取训练来打乱数据相关性,节约了存储空间,并且采用异步训练,大大加倍了数据的采样速度,也因此提升了训练速度。与此同时,采用多个不同训练环境采集样本,样本的分布更加均匀,更有利于神经网络的训练。

5. Example
CartPole
CartPole的玩法如下动图所示,目标就是保持一根杆一直竖直朝上,杆由于重力原因会一直倾斜,当杆倾斜到一定程度就会倒下,此时需要朝左或者右移动杆保证它不会倒下来。我们执行一个动作,动作取值为0或1,代表向左或向右移动,返回的observation是一个四维向量,reward值一直是1,当杆倒下时done的取值为False,其他为True,info是调试信息打印为空具体使用暂时不清楚。如果杆竖直向上的时间越长,得到reward的次数就越多。 
1 | # OpenGym CartPole-v0 with A3C on GPU |
Ref
- https://zhuanlan.zhihu.com/p/32438022
- David Silver ppt
- <https://www.youtube.com/watch?v=O79Ic8XBzvw >
- https://zhuanlan.zhihu.com/p/32596470
- http://pemami4911.github.io/blog/2016/08/21/ddpg-rl.html
- http://karpathy.github.io/2016/05/31/rl/
